Les méthodes de docking et de criblage virtuel à haut-débit pour la découverte d'inhibiteurs de protéines n'ont pas apporté la révolution espérée dans la recherche de médicaments. La quantité de nouvelles entités moléculaires approuvées par les agences de contrôle continue ainsi de stagner. Le développement d'algorithmes ne reposant pas sur des bibliothèques de molécules pré-établies s'est donc avéré nécessaire. De plus, la prise en compte de critères chimique/biochimique en amont est apparue comme essentielle.
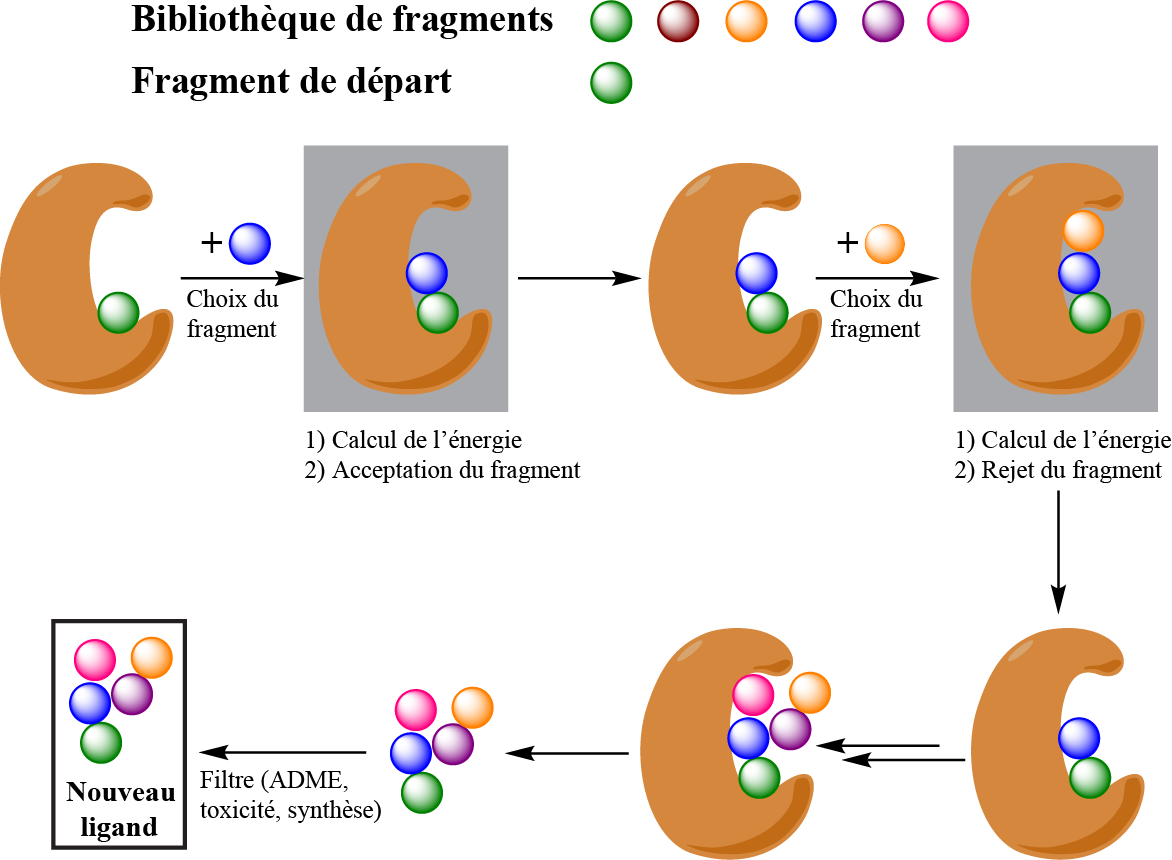
Nous présenterons une approche qui consiste à faire croître de nouvelles molécules au sein du site actif d'une protéine. Après avoir introduit un fragment initial au sein de la protéine, cette méthode ajoute progressivement de nouveaux fragments, en évaluant à chaque fois l'énergie d'interaction protéine/ligand, et retient ou non le fragment suivant un algorithme de Metropolis. Une sélection aléatoire des fragments conduirait à des molécules non stables, toxiques ou insolubles. L'analyse de bibliothèques de médicaments a permis d'extraire des propriétés statistiques (quelle est la probabilité qu'un phényl soit lié à un aldéhyde ?) qui sont ensuite utilisées pour la croissance des molécules (qui est ainsi biaisée). Les nouveaux ligands « ressemblent » donc aux molécules de la bibliothèque initiale. Les algorithmes SMoG et FOG développés au sein de notre laboratoire ont donc été réunis et optimisés.
Outre le biais dans la croissance, il est également possible d'analyser les molécules obtenues afin de ne retenir que les ligands présentant les meilleures propriétés phamaco-cinétiques (ADME) et toxicologiques, et accessibles par des voies de synthèse raisonnables. Un autre point crucial consiste à prendre en compte la flexibilité de la protéine : plusieurs études de recherche d'inhibiteurs ont échoué car elles se basaient sur une quantité limitée de conformations de la protéine. Conscients de ces échecs, nous avons développé nos algorithmes en prenant en compte dès le début cette problématique.
| Type : | : | affiche |
| Mots-Clés | : | ligand ; inhibiteur ; protéine ; biochimie ; docking ; croissance ; médicaments |
| PDF version | : |  PDF version PDF version |
- Image